You have probably come across tutorials, tweets or blog posts that talk about something called git. If you are like me, your eyes begin to glaze over as you think to yourself “Great! Another short-worded technical term that I have no clue about!” Well, fear not! Git falls under a broader technical topic called source control, and we can simplify source control into two pieces. First is the source, which is generally the group of files that you are working on. You’ve probably just called it your app or your project. Second is control, which allows you to control changes that are made to your project over time. Rather than the typical workflow you’re probably used to where you just save the file, control gives you granular access to your project at certain points in its development, allowing for more detailed editing. As we dive deeper, you’ll see why this is so helpful. This post will give us a solid foundation for diving into detail about source control. Before we do that, let’s imagine how we would keep track of all the changes a file will undergo before reaching the final copy without a source control system.
Build-A-Source Control
Let’s say that we have created a file called hello_world.rb and added a line of code to it. It’s the most elegant piece of code the world has ever seen and you don’t want to mess with this masterpiece. But then you learn about a cool feature you want to implement in your current hello_world.rb file. You want to add it in, but you also don’t want to touch that masterpiece. What would you do? We can just make a copy of our original file and then add our cool new feature to the copy. The file could be named hello_world_v2.rb and all our problems are fixed! Well, kind of. You see, our home-built source control system suffers from a scaling issue. When we say a scaling issue, imagine having to make a new file every time we wanted to keep a copy of our awesome code but still add a new feature to it . That could be hundreds, thousands of files to keep track of. I don’t know about you, but ain’t nobody got time for that! That’s ok though, because various source control systems have already solved this problem. Grab some coffee, cuz it’s time for a deep dive into the world of source control.
Getting Down to the “Source” of Source Control
Pinpointing the origins of source control can get a little hairy. We can trace it back to the early 70’s with early source control systems such as
Source Code Control Systems (SCCS), Revision Control System (RCS) and later, Concurrent Versions System (CVS). As we witnessed earlier, trying to maintain some semblance of organization with different versions of our files can prove tiresome and prone to error. Source control wanted to create an easy way to keep track of changes made to our project so that we can easily get back to older versions of our codebase.
This is particularly helpful for those times we add a new feature that has a bug we didn’t know about. It also solves other major problems like collaborating with multiple developers on the same codebase. Different source control systems implement this differently, but they generally use common terms and principles. Let’s examine those terms and principles that you will encounter when working with a source control system.
Terms and Principles. Also Known As “The Stuff Nobody Explains!”
Branches, commits, versions, yada, yada, yada! What’s it all mean? Going back to our fictitious hello_world.rb file, let’s go through the steps of how we would implement a modern source control system into our workflow. The explanations will be general, and we will be using a tree for an analogous comparison. Yes, a tree. This will work, I promise.
Repos, Staging, Commits Oh my!
When starting off a new project, the first thing developers do is initialize a repository.

A repository is the central location where the project is being kept and where changes will be tracked. Usually this will be a directory with many files in it, but for our purposes we will just have the one file in our directory. After we initialize the repository, we are within what is formally called the trunk, or more commonly known as the master branch of our project. This master branch forms the basis of our project, where the most stable and recent versions of our project will reside. You don’t want to build the latest and greatest features on the master branch because it will leave you with an unstable base with many bugs. Adding the latest and greatest features requires lots of testing before it should ever be implementing into the application. Even the best developers make mistakes from time to time. Just one mistake in your code can cause your application to go down, which leads you down the path of scrambling to fix the bug(s) while users are left with an unusable application.
From here, our source control system knows that we have a repository set up, but it needs a little guidance to automatically start saving all the changes you make to your files. The first thing we have to do is tell our source control system about the files within the repository we created. This is known as staging a file.
A seedling doesn’t know when to begin growing just by you looking at it and shouting “Grow!!!”. You need to stage it, give it a nice soil bed and a little water before it begins its journey.
Now that our source control system is keeping track of changes being made, the final piece is the famed commit.
The simplest way to think of a commit is imagining taking a snapshot of your project at its current state. This snapshot represents a certain point in your application that you want to save. As you make commits throughout the life of your project, you form a history of snapshots that can be traversed to see any changes made. It also allows you to revert to an early commit if you encounter problems with your application. With our one-line application, we want to make a commit to save the beginning stages of our project. Many years and many commits later, we can always look back at the initial commit fondly and know that it is still tucked away safe and sound if we ever need to revert back to it.
Can’t Have a Tree Without Branches
If you have a keen eye, you may have asked yourself the question “How are you supposed to create new features while keeping the master branch stable?”. By stable, we mean that our master branch, which has the most current code, is tested and free of bugs. To experiment and create new features, we use the tree’s branches!
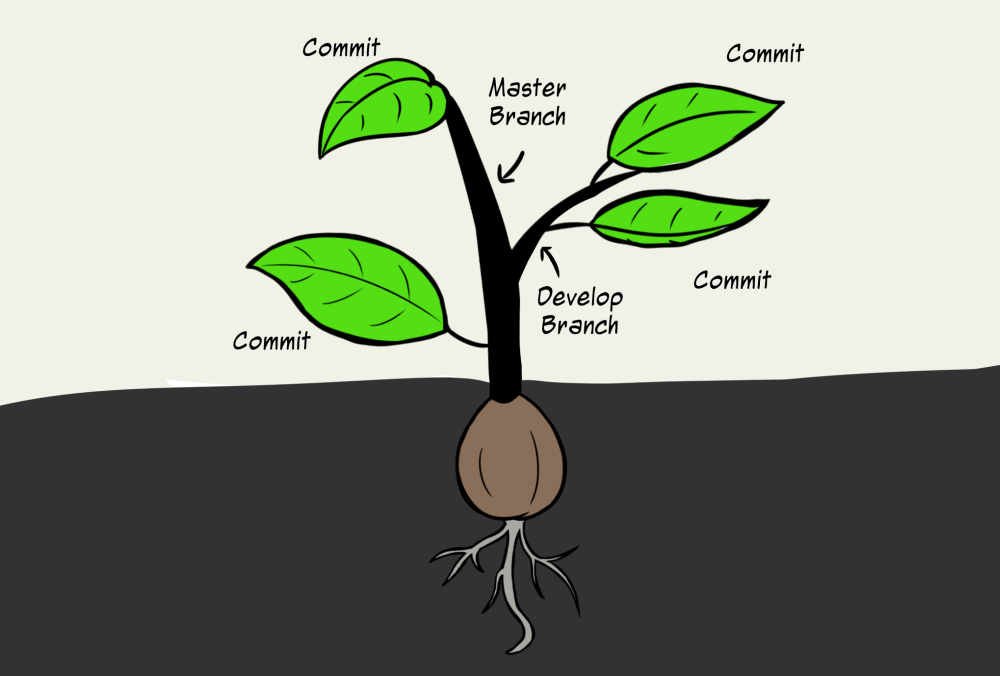
In the context of software development, when we create a new branch we are essentially branching away from the master branch so we can work on a new feature or bug fix without the risk of breaking something in our master branch. Once we’ve finished, tested it, and made sure it works, we can merge it back into the master branch.

Commonly, the branch is referred to as the feature branch, originally known as the topic branch. Within the feature branch, we are insulated from the master branch, so we can make changes, stage files and make commits separately. Once the feature or bug fix is complete we can merge in the changes made in the feature branch back into the master branch. The benefits of having separate branches for our features is that it allows us to further develop our project without breaking the working version of the application along the way. When implementing a source control system in this way, we end up with a beautiful development tree that gives us access to previous commits, branches that show the different features added on and, of course, a backup of our entire project. With the major terms under our belt, let’s talk about how source control is used within a development team.
You Get a Copy! YOU Get a Copy! WE ALL GET COPIES!
As is the case with development teams, there are usually many developers working on a single project together. How is it that they are able to do their work without interfering with each other? You guessed it. Source control! More specifically, having a source control system in place allows developers to work on their specific functionality separately from the other developers. When they are done, they can then merge their changes back into the master branch. Where source control really shines is the moment that you make a change that interferes with another developer’s changes. At that point, the source control system will pinpoint the conflict, also known as a merge conflict, and point out the lines that need to be resolved.

From that point the developers can work together to figure out the best way to fix the conflict and merge in the changes.
Modern source control systems are also known as Distributed Version Control Systems (DVCS). To understand what DVCS is, we need to look at how older source control systems were run. With an older source control system, the repository would be located on a central server that the development team would be able to access through the internet. When a developer wanted to add a feature or bug fix to the repository, they would grab the most recent copy of the repository from the server and begin their work. What made this cumbersome was the fact that the copy that you grabbed from the server is only a snapshot of the repository without the history of commits. Because of this, when it was time to merge in your changes, the developer would have to connect to the server, check to see if there have been any commits since they last copied the repository, bring in those changes, then commit their changes to the main repository. The drawback to all this is without an internet connection, you cannot commit changes to the repository.
To compound the problem, there is essentially only one true working version of the project, located on the central server. If anything were to happen to the server, it would be a hassle to piece back together a working project. All of this is very time consuming and as developers, we don’t like wasting time. We have cat videos to watch you know!
With a DVCS, every single copy of the repository functions as a complete repository with full commit history. When we checkout a repository in this system, we’re getting the full repo, with commits and everything, not just a snapshot. This allows for multiple backups that could function as the central repository. It also alleviates the time consuming process of making changes to a central repository due to the fact that your copy of the repository is a working copy of the repository. The benefits of a DVCS spread much farther than the above examples. A DVCS allows developers to work on a project without having to be connected to a network, people outside of the core team of a project to contribute to a project (also known as open-source contributions) and many other benefits too long to list. DCVS has changed the way we work with other developers and has fostered an open-source community around it.
A Life With Source Control
Source control not only gives us the basic needs of multiple copies and making changes without destroying previous versions of our project, but has made coding a social endeavour as well. From big projects to small, we can ensure that all of our code is easily maintained and managed. Join us next time for part two on our series about source control as we look at the three most popular source control systems in use today. Happy coding Code Newbies!
Illustrations by Sarah Frisk


